
Cloud AI vs On-Device AI: What’s the Difference?
Cloud AI and on-device AI both run the same fundamental process (inference),…
How to Reduce AI Inference Costs
Inference costs can quietly become your biggest AI expense. The best cost…
What Is Quantization in AI?
Quantization reduces the numerical precision of a model (e.g., from 32-bit floats…
What Is Distillation in Machine Learning?
Knowledge distillation is a technique where a large, accurate teacher model trains…
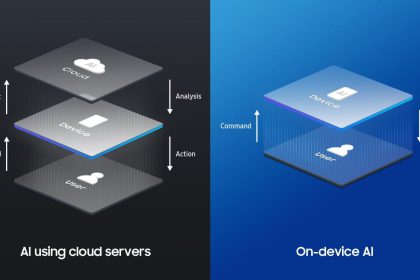
On-device AI vs cloud AI: privacy + speed
On-device AI (also called edge AI) runs machine learning models directly on…

On-Device AI Explained: Faster, Private, and the Next Big Shift
On-device AI is exactly what it sounds like: artificial intelligence that runs…
Running AI Locally with GPU Power: A Beginner’s Guide to NVIDIA’s Chat with RTX
Learn how to set up and use large language models (LLMs) like…
⚡ Training AI for Real-Time Applications: Challenges and Solutions 🔍🤖
Artificial Intelligence (AI) has become a powerful driver of innovation, but its…
