
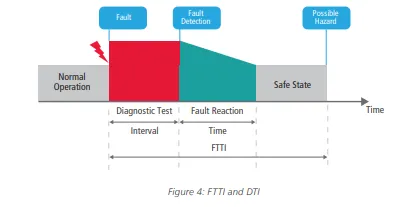
Timing Analysis

Prabhu TL is a SenseCentral contributor covering digital products, entrepreneurship, and scalable online business systems. He focuses on turning ideas into repeatable processes—validation, positioning, marketing, and execution. His writing is known for simple frameworks, clear checklists, and real-world examples. When he’s not writing, he’s usually building new digital assets and experimenting with growth channels.

Leave a review Leave a review


{kind=link}